This year, our professional internship turned into a large-scale interlinguistic hackathon! Students from UCU (not for the first time) and IFNMU (for the first time!) officially joined in the creation and annotation of large language corpora, thanks to the incredible coordinators Oksana Taran and Halyna Yurchak. ✨🤝
Our students demonstrated the utmost professionalism and managed to accomplish a colossal amount of work for the development of Ukrainian NLP:
1️⃣ Full meta-tagging of around 4,000 texts for the GRAC (General Corpus of the Ukrainian Language). The texts were downloaded from an online library with only the author and title. Now they have all the necessary attributes: date, style, original language and translator. The detective work was thrilling! The students searched for data on Wikipedia, in catalogues, archives and articles. They even wrote to a contemporary author to clarify the date of a work (unfortunately, he didn’t reply, but it was a valiant attempt! 😎).
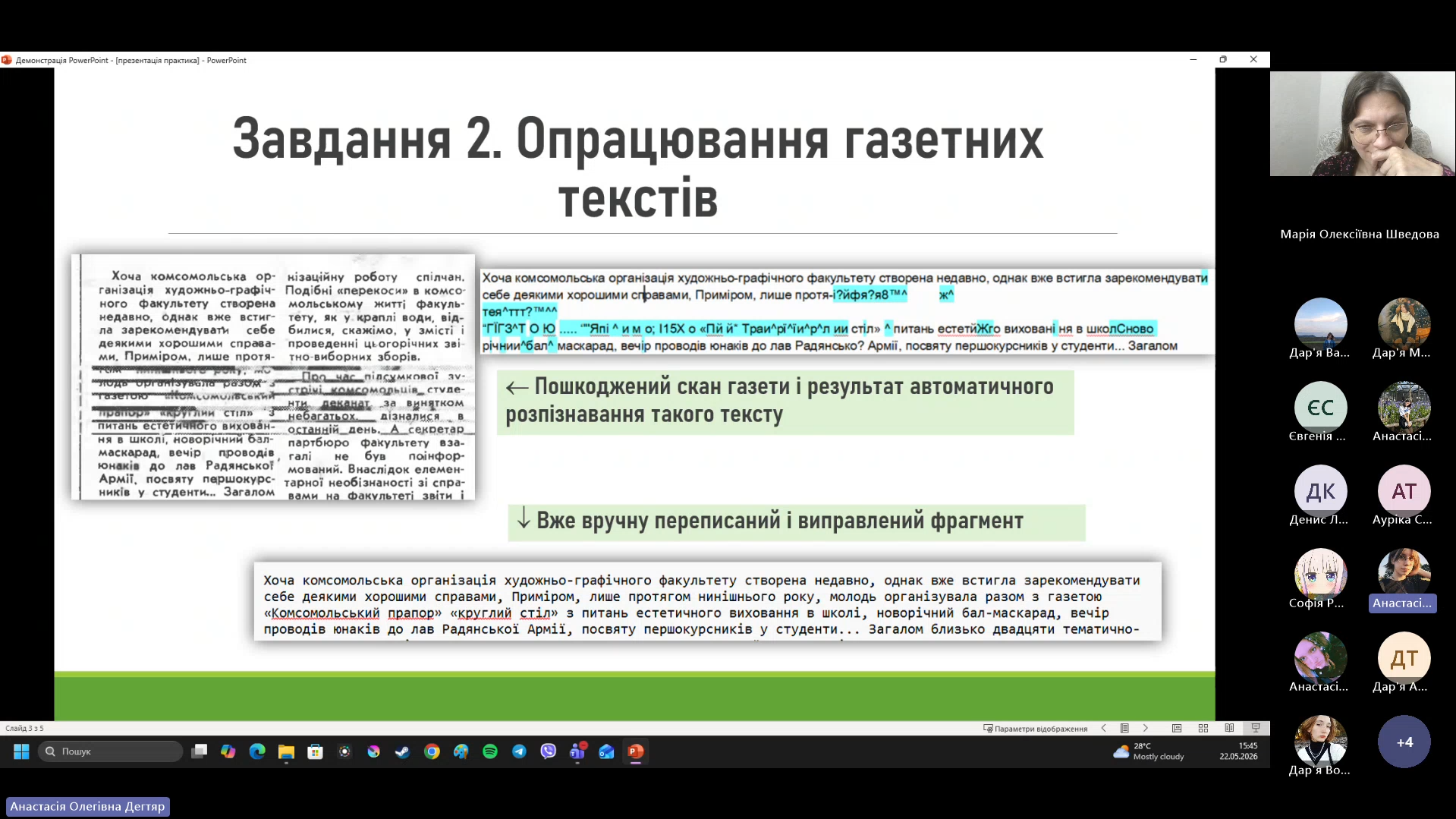
2️⃣ Digitisation and annotation of 54 newspapers from the late 1980s to the early 1990s. The total text volume amounted to 6 MB (that’s like 3–4 thick books!). Incidentally, during their analysis, the students concluded that printed newspapers of that era served as the social media of their time! 📰💬
3️⃣ Preparation and alignment of texts for parallel corpora in English, German and Spanish.
GRAC and ParaRook would like to extend our sincere thanks to our fourth-year students and colleagues for such a significant contribution to computational linguistics! You are absolute pros! 💎🛸